Before jumping into the big companies let’s define what ETL is. The ETL (Extract, Transform, Load) in Big Data refers to the process of extracting data from various sources, transforming it into a format suitable for analysis, and then loading it into a data storage or processing system for further analysis and reporting. ETL is a fundamental process in Big Data analytics as it enables organizations to collect, integrate, and analyze large volumes of data from diverse sources to gain valuable insights and make data-driven decisions.
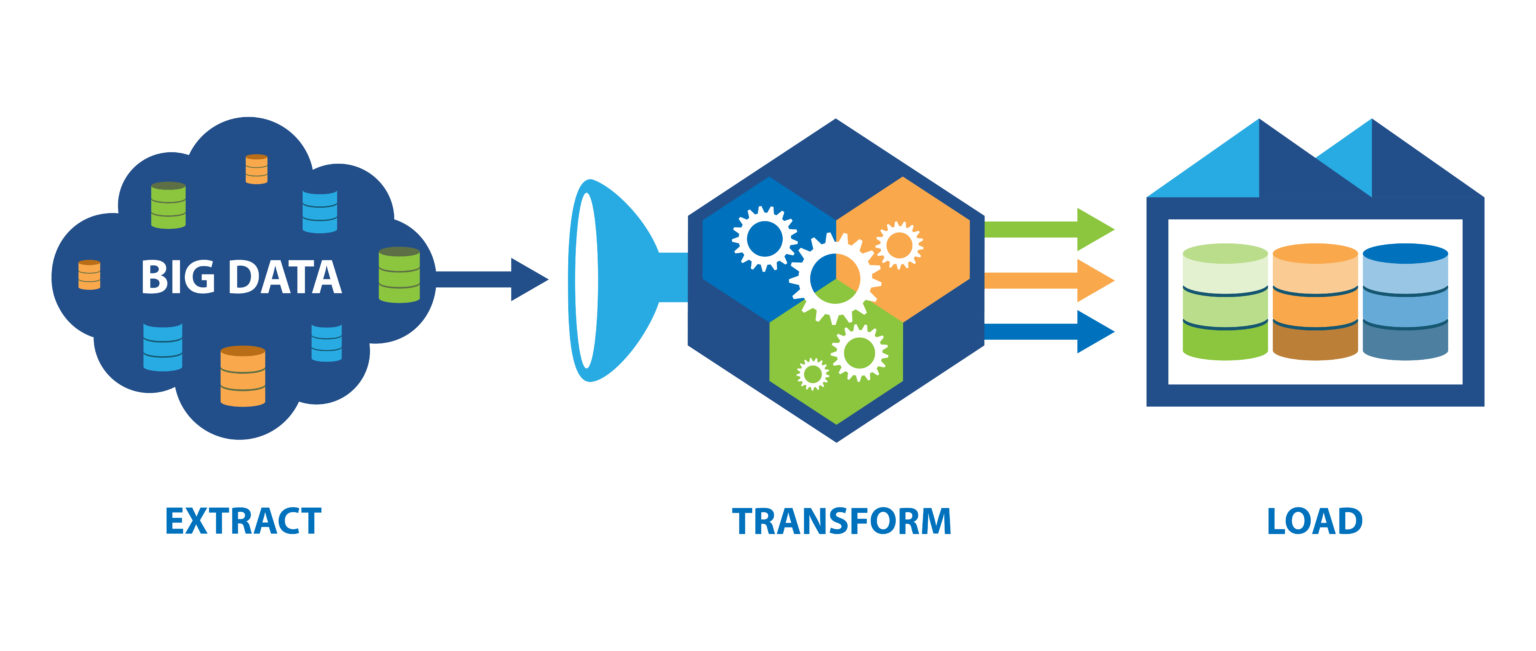
The ETL process in Big Data typically involves the following steps:
- Extract:
- Data is extracted from various sources, such as databases, logs, files, APIs, social media platforms, sensors, and more.
- Big Data platforms like Apache Hadoop, Apache Spark, and cloud-based storage services are often used to handle massive amounts of data during extraction.
- Transform:
- Data is cleaned, filtered, and transformed into a consistent and structured format suitable for analysis.
- This step involves data cleansing (or cleaning), data enrichment, data normalization, data aggregation, and other data processing tasks.
- Transformations may also include data integration from different sources to create a unified view of the data.
- Load:
- Transformed data is loaded into a data warehouse, data lake, or other storage and processing systems for further analysis.
- These systems allow for efficient data storage, retrieval, and querying, enabling data analysts and data scientists to perform complex analytics.
ETL in Big Data faces several challenges due to the volume, variety, velocity, and veracity of the data involved. Some of the key challenges include:
- Data Volume: Big Data ETL processes deal with massive volumes of data that can range from terabytes to petabytes or more. Efficient data processing techniques and distributed computing are essential to handle such large datasets.
- Data Variety: Big Data comes in various formats, including structured, semi-structured, and unstructured data. ETL processes need to handle diverse data types, such as text, images, videos, logs, and social media posts.
- Data Velocity: Big Data is generated and updated at a high velocity in real-time or near real-time. ETL processes must be designed to handle streaming data and ensure timely updates.
- Data Veracity: Ensuring data quality and accuracy is crucial in Big Data ETL. Data cleansing and validation techniques are employed to deal with potential inaccuracies in the data.
To address these challenges, organizations often use distributed data processing frameworks like Apache Hadoop, Apache Spark, and cloud-based Big Data services to perform ETL at scale. These frameworks enable parallel processing, fault tolerance, and scalability, making it feasible to process and analyze massive volumes of data efficiently. ETL in Big Data is a critical process that lays the foundation for data-driven insights and decision-making in modern data-driven organizations. It helps convert raw data into valuable information, enabling businesses to gain a competitive advantage and improve operational efficiency.
Big companies like Google and Facebook do use ETL (Extract, Transform, Load) processes as part of their data management and analytics strategies. These companies deal with massive amounts of data generated by their users and systems, and ETL plays a crucial role in managing and processing that data for various purposes. ETL enables big companies to handle the massive scale of data generated by their platforms, derive valuable insights from it, and improve user experiences through data-driven decision-making.
They use ETL (Extract, Transform, Load) in various ways to manage and process their large-scale data. Here are some common ways in which big companies use ETL:
- Data Integration: Big companies often have multiple data sources and systems that generate diverse data. ETL processes are used to integrate data from these different sources into a unified format. This integration allows companies to have a comprehensive view of their data and make data-driven decisions based on a holistic understanding of their operations.
- Data Warehousing: ETL is employed to load data into data warehouses, which are optimized for analytical queries and reporting. Data warehouses provide a centralized repository for historical data, making it easier for analysts and data scientists to explore and analyze information.
- Real-time Data Processing: Some big companies deal with streaming data, such as user interactions in real-time applications. ETL processes are adapted to handle streaming data, enabling companies to gain insights and respond to events as they happen.
- Data Cleansing and Enrichment: ETL processes perform data cleansing, where inconsistencies, errors, and duplicates are identified and corrected. Additionally, data enrichment may involve combining data from different sources to enhance its value and context.
- Data Migration: Big companies often undergo system upgrades, migrations, or consolidations. ETL is utilized to migrate data from legacy systems to new ones while ensuring data integrity and accuracy during the process.
- Data Transformation and Aggregation: ETL processes transform data into a suitable format for analysis and reporting. Aggregation and summarization of data are also performed to create useful insights and reduce the volume of data.
- Business Intelligence and Analytics: ETL plays a vital role in feeding data into business intelligence tools and data analytics platforms. It enables data analysts and data scientists to derive valuable insights from the data and make informed decisions.
- Data Governance and Compliance: ETL processes can incorporate data governance rules and enforce data quality standards. By ensuring data quality and compliance, big companies maintain the integrity and security of their data, which is crucial for meeting regulatory requirements.
- Data Archiving: ETL is used to archive historical data that is no longer frequently accessed but needs to be retained for compliance or historical analysis purposes.
- Scalability and Performance: Big companies deal with massive volumes of data, and ETL processes need to be highly scalable and efficient. Parallel processing and distributed computing are often utilized to handle large datasets efficiently.
Of course, the processes of using data in companies with heavy amounts of data could be more complicated or mysterious! I tried to cover some common processes of ETL, hope it is useful.